INFO
笔记
Background
在深度学习硬件崛起之前,大多数的科学计算都是是基于 IEEE Float32 和 IEEE Float64 的。 随着深度学习的发展和 AI 处理器的演进,大家发现在 training 和 inference 的过程中,可以通过降低浮点运算的精度来有效的提升运行速度,功耗和芯片面积。那么,这给厂商提供了足够的自由度,来设计自己的浮点类型,从而取得 AI 系统性能和精度的平衡。
模型规模的持续扩大,导致模型训练和部署所需求的算力和功耗持续的扩张。面对算力的挑战,降低精度是一把利器,从最初的 FP32,到 16-bit 的 FP 的推出 (FP16和BF16),和一些定制的浮点类型的推出,如 TF32 等等。
浮点数
浮点数由三部分组成:符号位(sign)、指数部分(exponent)、尾数部分(mantissa)
- 决定了数的取值范围,默认值为 127
- 规定尾数部分最高位必须是 1,1 不保存就可以节省出 1 位用于提高精度,因此最高位的 1 是隐含的(Implied)
(1)十进制整数 17 Fp32
- sign = (0)2
- exponent = (10000011)2
- exponent - bias = (128 + 2 + 1) - 127 = 4
- mantissa = (00010000……)2
(2)十进制数 3.25 Fp32
- sign = (0)2
- exponent = (10000000)2
- exponent - bias = 128 - 127 = 1
- mantissa = (10100000……)2
FP64(Float Point,双精度浮点数)
- 符号位 1 bit
- 指数位 11 bit
- bias = 1023
- 尾数位 52 bit
FP32(单精度浮点数)
- 符号位 1 bit
- 指数位 8 bit
- bias = 127
- 尾数位 23 bit
TF32(Tensor Float)
TF32 是由 Nvidia 提出,首发于 A100 GPU 中。 TF32 的名字会有点 confusing,其实它并没有 32-bit,相反它只有 19-bit,更应该称为 BF19。
FP16(半精度浮点数)
- 符号位 1 bit
- 指数位 5 bit
- bias = 15
- 尾数位 10 bit
BF16(BFloat)
BF16 的提出是为了解决 FP16 在 deep learning 应用中遇到的一些问题。
- BF16 和 FP32 的 range 是一致的,远大于 FP16 的 6.5e4。缺点则是 BF16 只有 7 个 bit 的 mantissa,精度上是低于 FP16。
- BF16 基本上可以看作成一个“截断”版的 FP32,两者之间的转换是非常直接,其实现电路也会非常简单。 BF16 和 FP32 之间的转换在 training 的过程中是会频繁发生的,BF16 的使用能有效的降低电路的面积。
BF16 首先是在 Google 的 TPU 中得到支持,其后在业界得到了广泛的支持。当前主流的硬件厂商都对 BF16 做了深度的优化实现。
FP8
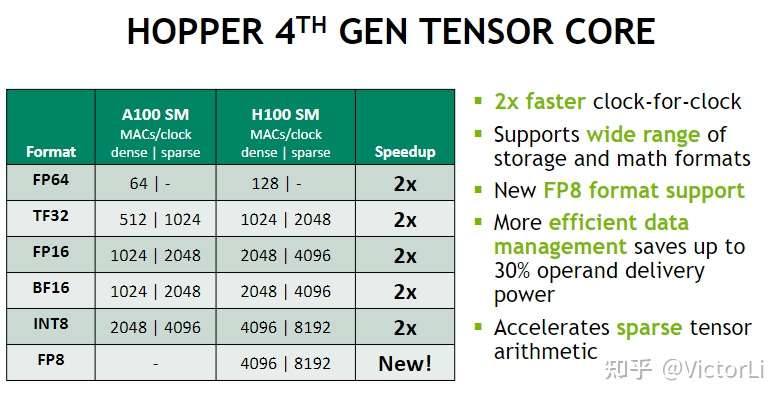
2022年,Nvidia 发布的最新一代高性能 GPU 架构:H100。H100 TensorCore 中引入了一种新的浮点类型 FP8。相较于 FP16/BF16,FP8 能取得到 2x 的性能提升,4096 MAC/cycle 的水平。

有两种形式,E5M2 和 E4M3
- E5M2
- 指数位 5 bit
- 尾数位 2 bit
- E4M3
- 指数位 4 bit
- 尾数位 3 bit
HFP8
Hybrid FP8:forward 的时候用 FP-1-4-3,backward的时候用 FP-1-5-2。forward 的时候更关注精度,backward 的时候更注重范围。这样的话,HFP8 就能够在训练的过程中获得接近 FP32 的表现。
Conclusion
- 不同的浮点类型可以给算法和应用带来非常大的自由度,可以选择最合适的设计来满足功耗、性能、精度的要求。尤其对于那些从应用到芯片都自己开发的厂商,比如 MSFP 和 Tesla Dojo
- 硬币的另一面则是不同的浮点类型可能并不好移植到别的硬件,比如 CFloat8 就很难在 Nvidia 的硬件上得到加速;同样,TF32 可能只能在 Nvidia 上得到支持